
2023年11月28日,中电信人工智能科技有限公司(以下简称:电信AI公司)成立。它是中国电信开展大数据及人工智能业务的科技型、能力型、平台型专业公司。2023年,电信AI公司在全球21场顶级AI竞赛中屡获殊荣,申请专利100余项。同时,该公司在CVPR、ACM MM、ICCV等权威会议和期刊上发表了30余篇论文,充分展现了国资央企在人工智能领域的实力和决心。
该公司注册资本为30亿元,前身为中国电信集团的大数据和AI中心。作为一家专注于人工智能技术研发和应用的公司,他们致力于核心技术的研究、前沿技术的探索以及产业空间的拓展,旨在成为百亿级的人工智能服务提供商。在过去两年里,该公司自主研发了星河AI算法仓赋能平台、星云AI四级算力平台以及星辰通用基础大模型等一系列创新的成果。目前,公司员工规模超过800人,平均年龄仅31岁。其中,研发人员占比高达80%,且70%的员工来自国内外知名互联网企业和AI领军企业。为了加速大模型时代的研发进程,公司拥有超过2500块等效于A100的训练卡,并配备了300多名专职数据标注人员。此外,公司还与上海人工智能实验室、西安交通大学、北京邮电大学、智源研究院等科研机构紧密合作,结合中国电信6000万视联网和数亿用户场景,共同推动人工智能技术的创新和应用。
本期介绍电信AI公司TeleAI团队在CVPR 2023 AI CITY CHALLENGE顶会上取得的重大突破,获得了Challenge Track 5: Detecting Violation of Helmet Rule for Motorcyclists赛道的冠军。CVPR是计算机视觉领域的三大顶级会议之一,享有极高的业内声誉。该冠军技术不仅在学术界获得了认可,还在城市治理实际业务中取得了显著的应用效果,已经落地多个项目。本文将深入介绍该团队在本次挑战中所采用的算法思路和解决方案,为CV领域的研究和应用贡献了有价值的经验和实践。
CVPR 2023 AI CITY CHALLENGE Track 5: Detecting Violation of Helmet Rule for Motorcyclists冠军技术分享。

【赛事概览与团队背景】
AI City Challenge由英伟达、亚马逊、马里兰大学等发起,自2017年起,每年举办一次。该挑战赛主要集中在智能交通相关的车流统计、车辆重识别、跨摄像头跟踪、异常事件分析等应用场景,被誉为“智能交通视频分析界的ImageNet竞赛”。
由中国电信AI公司行人算法方向的成员组成的TeleAI团队,参加了本次比赛。该团队在计算机视觉技术这个研究方向深耕,积累了丰富的经验。他们的技术成果已在城市治理、交通治安等多个业务领域中广泛应用,持续服务海量的用户。TeleAI团队以本次CVPR 2023 AI CITY CHALLENGE的Detecting Violation of Helmet Rule for Motorcyclists赛道为契机,实现在智慧安防领域技术的自我突破。
1引言
检测摩托车驾驶员和乘客未佩戴头盔的违规行为是一项关键的计算机视觉任务,对于保障摩托车行驶过程中的生命安全具有重要意义。这一异常事件检测问题可视为目标检测任务,即识别图像中摩托车驾驶员和乘客的位置以及判断其是否佩戴头盔。为解决这一问题,本文提出了Motorcycle Helmet Object Detection Framework(MHOD)。
首先,我们采用目标检测网络DETA来预测视频中所有对象的位置和类别,并通过两个模型的集成来提高准确性和鲁棒性。鉴于乘客类别训练数据的稀缺性,我们设计了基于目标跟踪的乘客召回模块(PRM),显著提升了乘客类别的召回率。最后,引入了类别细化模块(CRM),结合视频中的时间信息来校正类别。在AI City Challenge 2023 Track5中,我们提出的框架在挑战的公共排行榜上取得了显著的成绩。
2 赛题介绍和难点
在不同的光照条件和摄像机角度下精确检测是否佩戴头盔是一项具有挑战性的任务。首先,在交通监控系统中,摄像头通常安装在相对较高的位置,导致视频分辨率较低。此外,如图1所示,光照、天气、模糊等因素也会增加识别的难度。为了克服这些复杂场景并提高模型的鲁棒性,我们采用了模型集成[4]的策略,详细内容将在第3.2节中进行描述。

如表1所示,我们对训练数据集中每个类别的目标数量进行了统计,发现存在严重的类别不平衡问题,尤其是在Passenger 2的数据相对较少。具体而言,Passenger 2仅出现在两个视频中,分别是005.mp4和091.mp4。我们在图2中对样本进行了可视化,观察到在005.mp4中,Passenger 2是摩托车前面的一个小孩,这会使模型对该目标的识别变得非常困难。而在091.mp4中,Passenger 2位于摩托车后部,这种情况则相对符合我们的预期。
3 解决方案
3.1 概述
MHOD框架的概述如图3所示,通常包括三个主要部分。首先,我们采用集成技术来提高性能。在第二部分中,执行乘客召回模块(PRM),旨在提高乘客类别的召回率。第三部分是类别细化模块(CRM),致力于减少同一轨迹中类别的切换次数。所有这些模块和组件将在接下来的章节中进行详细描述。
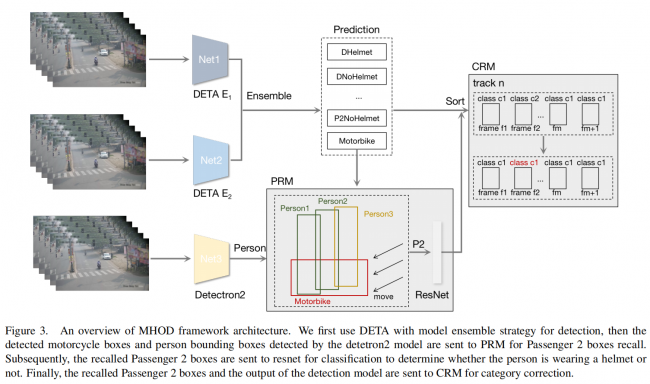
3.2模型集成
由于视频场景的复杂变异性和低分辨率,我们提出的框架采用不同初始化过程的模型集成以提高性能。本文使用的目标检测方法基于Transformer的DETA算法[13]。相较于最近的方法[3, 18],DETA展示了一种更为简单的替代训练机制。这种替代机制在训练效率方面具有显著优势,尤其是在短训练周期内表现出色。我们从每个视频帧中使用检测模型获取检测到的对象的边界框和相应的置信度:
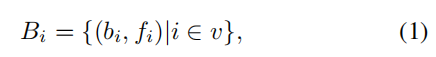
其中,bi是相应的边界框信息,fi是时间帧,v是视频的帧长度。在获取检测结果后,我们得到一个边界框b = (cls, xc, yc, w, h, s),其中cls是边界框的类别ID,(xc, yc)是中心点的位置,(w, h)是边界框的宽度和高度,s是置信度分数。我们进行非极大值抑制(nms)以过滤重叠的检测框,这些框可能涉及相同的对象。因此,通过使用nms从两个独立模型提取的最终预测通常被表述如下:
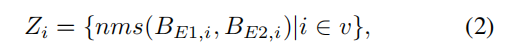
其中,Z代表最终的预测。E1和E2都是在AI City Challenge数据集上微调的DETA模型。
3.3 Passenger Recall Module 模块
基于表1中呈现的训练集统计结果,Passenger 2的样本数量极少。因此,我们采用后处理技术来优化Passenger 2的检测边界框。我们使用在COCO数据集[9]上预训练的开源框架Detectron2 [17]来获取人的边界框集合P = {p1, p2, p3, · · · },其中p = {xc, yc, w, h, s, f}。从Z中获取摩托车的边界框集合M = {m1, m2, m3, · · · }。对于M中的每个mi,在满足以下条件时,记录与mi匹配的所有pj ∈ P:
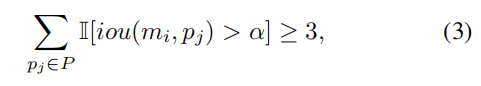
其中,α是控制IoU大小的系数,iou(x, y)表示边界框x和y之间的交并比(IoU)。使用SORT [2]来预测人的边界框的轨迹,并记录人的运动方向,之后根据连续帧之间的相关性计算每个边界框的运动方向,Passenger 2是轨迹方向上的最后一个人的边界框。此外我们在训练集上训练一个分类网络,用于判断Passenger 2是否佩戴头盔。
3.4 Category Refine Module 模块
在视频中,我们发现随着非机动车辆驶出摄像头的视野,模型预测的标签会随着目标逐渐变小而改变。受到跟踪思想的启发,同一跟踪 ID 的相应框在运动过程中类别不应该发生改变。SORT [2] 是一种典型的基于检测的跟踪方法。我们通过SORT获得摩托车和行人的轨迹,计算该ID中所有帧的类别,当某个类别的频率超过给定跟踪ID的总检测次数的50%时,我们将该ID上所有帧均改为该类别标签。
4 实验结果
4.1 评估指标
本次挑战赛使用的评估指标是mAP,即所有目标类别上平均精度(Precision-Recall曲线下的面积)的均值。
4.2 实验细节
模型在AI City Challenge数据集上经过8个epochs的微调,使用Adam优化器,学习率为5e-6,权重衰减为1e-4。在训练过程中,图像的短边尺度从[720, 768, 816, 864, 912, 960, 1008, 1056, 1104, 1152, 1200]中随机选择,而长边不超过2000像素。在测试阶段,短边被固定为1200像素。模型加载了在Objects365 [16]数据集上预训练的参数。对于用于集成的两个模型,它们在初始化阶段的查询方面有所不同,分别设置为300和900。
对于判断是否戴头盔的分类模型,采用了在ImageNet预训练的ResNet-18 [8],并在AI City Challenge数据集上进行微调。输入分辨率为256×192,训练和测试数据集的比例为9:1。使用CosineAnealingLR的学习率衰减策略进行100个epochs的训练,学习率为0.04,权重衰减为5e-4。
4.3 实验结果
Table 2是消融实验的结果。集成模型会比DETA的基线高17.14%。PRM模块也会显著提升算法效果。此外,我们对训练集中的090.mp4进行了可视化,可以看到第12帧(图5a)中id为42的对象预测类别是DHelmet,但在的第24帧(图5b)中,它被预测为P1NoHelmet,使用CRM策略可以将该错误预测修正为DHelmet。


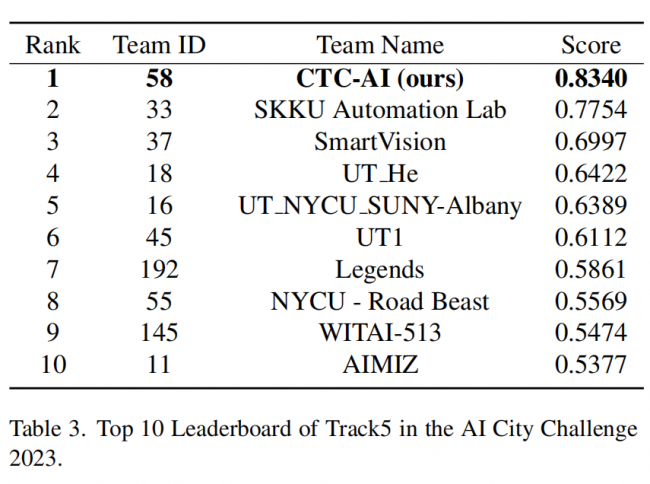
所提出的方法在AI City Challenge 2023的Track5验证集上进行评估。如表3所示,我们的方法取得0.8340的分数。
5 结论
在本文中,我们提出了一种名为MHOD(Motorcycle Helmet Object Detection)的框架,旨在检测骑摩托车者是否正确佩戴头盔。MHOD模块利用目标检测网络来预测视频中所有目标的位置和类别。为了提高乘客类别的召回率,我们引入了乘客召回模块(PRM)进行跟踪细化,并通过类别细化模块(CRM)来校正目标的类别。PRM是一个可扩展的模块,主要针对Passenger 2进行召回,而未来可进一步发展适用于Passenger 1的策略,以提升框架的效果。我们在2023年AI City Challenge Track5的公共测试集上进行的实验表明,我们的方法取得了0.8340的分数,证明了该方法的有效性。
我们的优异成绩充分彰显了团队方法的卓越效能,成功地将实际业务中积淀的算法、技巧以及算法逻辑应用到国际竞技舞台,实现了电信AI公司在智慧安防、城市治理领域的巨大突破。电信AI公司一贯坚守“技术源自业务,服务于业务”的发展理念,将竞赛视为检验和提升技术能力的至关重要平台。积极参与竞赛的过程中,我们持续优化和完善技术方案,为客户提供更高质量的服务,同时也为整个团队成员提供了珍贵的学习和成长机会。这一过程不仅不断提升了我们的竞争实力,也推动着整个团队在不断挑战中迈向更加辉煌的发展。
References
[2] Alex Bewley, Zongyuan Ge, Lionel Ott, Fabio Ramos, and Ben Upcroft. Simple online and realtime tracking. In 2016 IEEE International Conference on Image Processing (ICIP), pages 3464–3468, 2016. 2, 3, 4, 5
[3] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-toend object detection with transformers. In Computer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16, pages 213–229.Springer, 2020. 3
[4] A. Casado-Garc´ıa and J. Heras. Ensemble methods for object detection, 2019. https://github.com/ancasag/ensembleObjectDetection. 1
[8] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. IEEE, 2016. 5
[9] Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Doll´ar. Microsoft coco: Common objects in context, 2015. 3
[13] Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, and Philipp Kr¨ahenb¨uhl. Nms strikes back, 2022. 1, 3, 5
[16] Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365:A large-scale, high-quality dataset for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019. 5
[17] Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick. Detectron2. https://github.com/facebookresearch/detectron2, 2019. 3, 5
[18] Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M. Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection, 2022. 3
标题:中国电信AI顶会竞赛及论文专题回顾系列之三
地址:http://www.rgmgy.com//rmjj/41404.html
心灵鸡汤:







